| Python使用selenium库实现网页自动化登陆以及数据抓取(爬虫)教程 | 您所在的位置:网站首页 › python frame框架抓取 › Python使用selenium库实现网页自动化登陆以及数据抓取(爬虫)教程 |
Python使用selenium库实现网页自动化登陆以及数据抓取(爬虫)教程
|
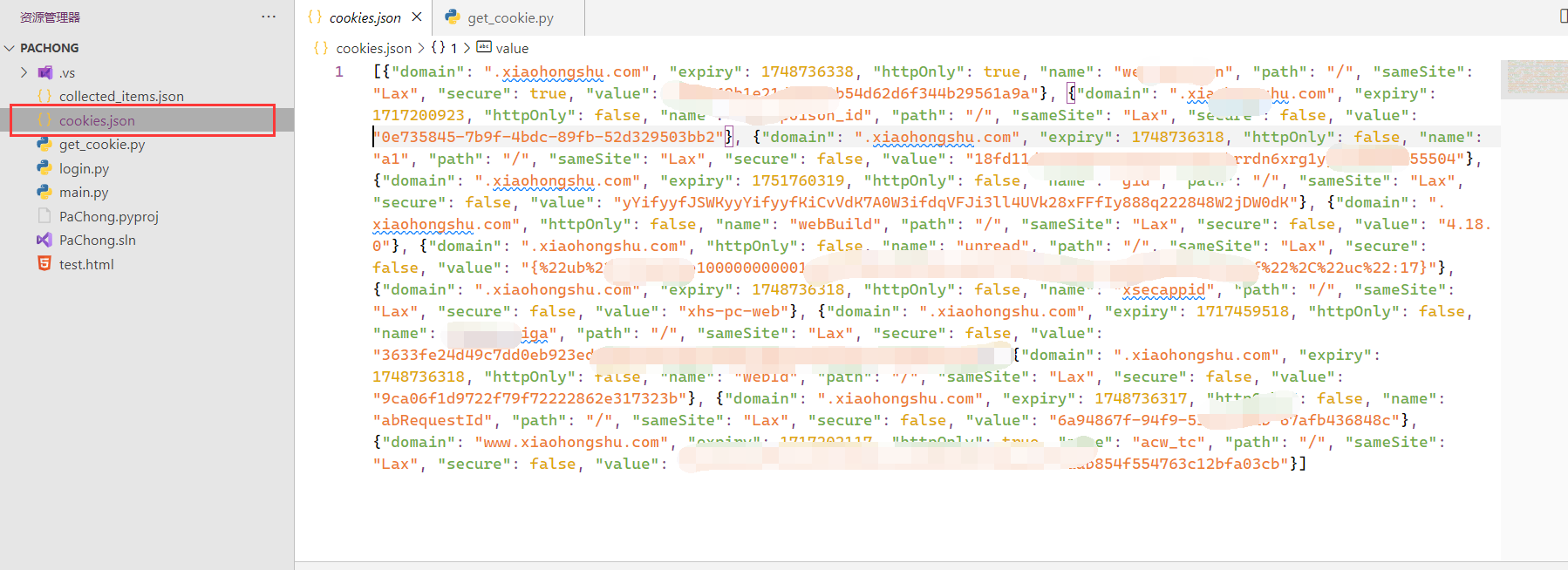
相比于传统的网络请求实现爬虫,Selenium可以模拟用户在浏览器上的操作,处理由JavaScript生成的动态内容,以执行点击、滚动、表单提交等操作,模拟真实用户访问,绕过一些反爬机制,更方便的获取动态生成的网站数据。 本篇教程将采取环境搭建、自动化操作、使用cookie自动化登陆、实现抓取数据等四个步骤循序渐进的讲解如何完成网页数据的获取。 一、工欲善其事,必先利其器(环境搭建) 1、安装Python坏境,使用其他版本或者电脑已有Python环境可跳过。 3.12.1版本Python下载地址 2、安装谷歌浏览器和下载同版本号的ChromeDriver,也就是谷歌浏览器驱动.大版本号必须一致,比如你的谷歌浏览器为125开头版本,驱动也必须下载125版本。点击地址下载安装即可。ChromeDriver不需要安装,解压到本地即可。如果你使用其他版本的Chrome浏览器和ChromeDriver也是可以的,只要保证两者的大版本号相同。版本号不同无法驱动浏览器。 125.0.6422.141版本Chrome浏览器下载地址 125.0.6422.141版本ChromeDriver下载地址 3、安装Selenium库,在已安装Python环境之后,控制台运行: pip install selenium二、让你的浏览器拟人化(自动化操作) 环境搭建完毕,我们就开始进入敲代码环节。第一个环节,让你的浏览器自己动起来。新建一个Python项目,创建open_baidu.py的python文件,开始我们的代码。完整代码: from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time # 配置 ChromeDriver 路径,替换为你的 ChromeDriver 路径,你也可以将chromedriver拖入文件根目录,使用'./chromedriver.exe'路径。 chrome_driver_path = 'D:/JIAL/JIALConfig/chromedriver/chromedriver.exe' # 替换为你的 ChromeDriver 路径 # 初始化 ChromeDriver Service service = Service(chrome_driver_path) # 打开浏览器时的相关配置,可以根据需求进行打开和关闭 options = Options() options.add_argument("--start-maximized") # 启动时最大化窗口 # options.add_argument("--disable-blink-features=AutomationControlled") # 使浏览器不显示自动化控制的信息 # options.add_argument("--disable-gpu") # 禁用GPU硬件加速 # options.add_argument("--disable-infobars") # 隐藏信息栏 # options.add_argument("--disable-extensions") # 禁用所有扩展程序 # options.add_argument("--disable-popup-blocking") # 禁用弹出窗口拦截 # options.add_argument("--incognito") # 启动无痕模式 # options.add_argument("--no-sandbox") # 关闭沙盒模式(提高性能) # options.add_argument("--disable-dev-shm-usage") # 使用/dev/shm分区以避免共享内存问题 # options.add_argument("--remote-debugging-port=9222") # 启用远程调试端口 # 初始化 WebDriver,并传入 ChromeDriver Service driver = webdriver.Chrome(service=service, options=options) # 打开百度搜索首页 driver.get("https://www.baidu.com") # 打印页面标题 print(driver.title) # 延时5秒钟,也就是浏览器打开5秒钟,避免闪退 time.sleep(5) # 关闭 WebDriver driver.quit()首先配置你的ChromeDriver的地址,然后初始化driver并对你要打开的浏览器窗口进行一些属性配置。运行这个python文件,电脑就会自动启动你的浏览器并打开百度搜索的主页。 接下来让我们基于这一段简单的代码扩充一下,尝试让浏览器自动打开百度搜索,并在搜索框填入要搜索的内容,自动点击百度一下按钮,来进行搜索。这里就涉及到对页面的html元素进行获取和操作。在我们想要获取内容的网页,按下F12,浏览器进入开发者模式,我们就可以检视此页面的html元素。在这里我建议大家熟悉一下xpath选择语法,当然selenium提供了通过id、class和xpath多种途径来获取元素,但是xpath可以综合层级、id和类名来选取元素,会在复杂的页面更精准的定位到我们所需要的数据,以下是完整代码,具体操作见注释: from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time # 配置 ChromeDriver 路径,替换为你的 ChromeDriver 路径,你也可以将chromedriver拖入文件根目录,使用'./chromedriver.exe'路径。 chrome_driver_path = 'D:/JIAL/JIALConfig/chromedriver/chromedriver.exe' # 替换为你的 ChromeDriver 路径 # 初始化 ChromeDriver Service service = Service(chrome_driver_path) # 打开浏览器时的相关配置,可以根据需求进行打开和关闭 options = Options() options.add_argument("--start-maximized") # 启动时最大化窗口 driver = webdriver.Chrome(service=service, options=options) try: # 打开百度首页 driver.get("https://www.baidu.com") # 显式等待,直到搜索框出现 wait = WebDriverWait(driver, 10) # 通过Xpath表达式获取到百度输入框的html元素,方法也提供By.ID和By.CLASS_NAME的方法,用户可自动尝试 search_box = wait.until(EC.presence_of_element_located((By.XPATH, "//input[@id='kw']"))) # 输入搜索关键词 search_box.send_keys("原神") # 模拟按下回车键进行搜索 search_box.submit() # 等待搜索结果加载完成 wait.until(EC.presence_of_element_located((By.XPATH, "//div[@id='content_left']"))) # 打印搜索结果的标题 print(driver.title) # 延时五秒展示结果 time.sleep(5) finally: # 关闭浏览器 driver.quit()三、不能解放双手叫什么自动化(获取cookie自动登录) 在平常的使用中,一些需要登陆的网站例如CSDN、小红书等,在我们登陆一次之后,浏览器就会保存我们的登陆信息,之后打开这个网站都是已登录状态,不需要重复登陆(除非登陆过期或手动删除cookie)。但是我们通过自动化工具打开浏览器,每一次都相当于打开一个新的浏览器,哪怕手动登陆很多次,下一次自动打开也不会有你的登录信息,依然需要手动登录,况且有些网站是需要登陆后才能进行数据搜索获取(例如小红书),那我们岂不是每一次自动打开网页,都要手动的登陆一下再操作?这样可就太不自动化了!一个合格的自动化操作,顶多可以接受我第一次登陆,之后每次都像是普通浏览器一样自动登录,要解决这个问题,就要开始我们的第三步,获取登陆的cookie保存到文件,后续自动读取cookie用来实现自动登陆。根据刚才的步骤,我们现在可以很轻松的写出打开网站并停留一段时间供我们登陆的代码,登陆完成之后使用driver.get_cookies()方法便可以获取我们的登录信息(以小红书为例)。在项目中新建一个get_cookies.py的Python文件,先给出完整代码: import os import json from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options import time # 设置 ChromeDriver 路径(替换成你自己的路径) chrome_driver_path = "D:/JIAL/JIALConfig/chromedriver/chromedriver.exe" # 配置 Chrome 选项 options = Options() options.add_argument("--disable-blink-features=AutomationControlled") driver = webdriver.Chrome(service=Service(executable_path=chrome_driver_path), options=options) try: # 打开小红书主页并手动登录 driver.get("https://www.xiaohongshu.com") time.sleep(40) # 给用户足够的时间手动登录 # 获取登录后的 cookie cookies = driver.get_cookies() # 打印当前工作目录 print("Current working directory: ", os.getcwd()) # 将 cookie 保存到文件 with open("cookies.json", "w") as file: json.dump(cookies, file) print("Cookies saved successfully.") finally: driver.quit()运行这个get_cookies.py文件后,浏览器会自动打开小红书的网页,并停留40秒钟,我们需要手动进行登陆账号,然后等待程序运行结束,在项目根目录下就会生成一个cookies.json的JSON格式的文件,打开这个文件,就可以查看到我们账号登陆的cookie信息了,如下图所示:
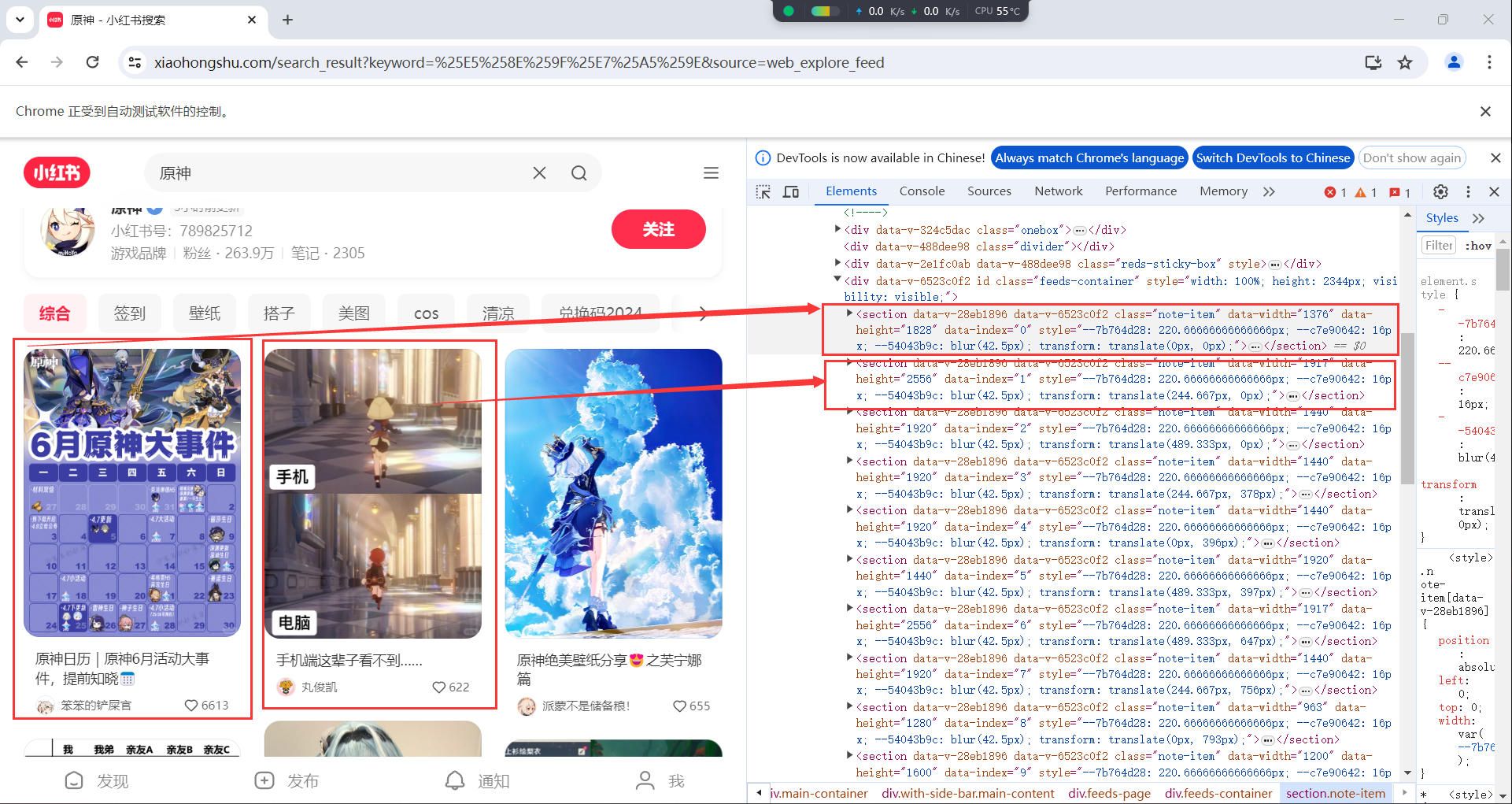
有了这个文件,我们就可以实现浏览器自动登录,不用再需要我们手动进行登陆了,具体实现方法让我们来到下一个步骤。 四、授人以鱼不如授人以渔(自动化数据获取[爬虫]) 来到了我们最后一个步骤,也是最重要的步骤,抓取网页中我们需要的信息并存储到文件中。我们还是以小红书网站举例,让我们新建一个main.py的Python文件,第一步读取本地cookie文件实现自动登录: driver.get("https://www.xiaohongshu.com") time.sleep(5) # 等待页面加载 # 从文件加载 cookie with open("cookies.json", "r") as file: cookies = json.load(file) # 注入 cookie for cookie in cookies: driver.add_cookie(cookie) time.sleep(5) driver.refresh() # 刷新页面以加载注入的 cookie time.sleep(5)先来看这段代码,打开主页之后,从我们的cookies.json文件中读取cookie并通过driver.add_cookie()的方法,将登录信息注入到浏览器,注入成功之后刷新页面,我们的自动登录就完成了(如果没有登陆成功检查一下cookie是否过期,可以从第三步骤重新尝试)。登录之后,我们来自动搜索我们想要的内容。 # 显式等待,直到搜索框出现 wait = WebDriverWait(driver, 10) search_box = wait.until(EC.presence_of_element_located((By.XPATH, "//input[@placeholder='搜索小红书']"))) search_box.send_keys("原神") time.sleep(5) search_button = wait.until(EC.element_to_be_clickable((By.XPATH, "//div[@class='input-button']"))) search_button.click() time.sleep(5) wait.until(EC.presence_of_element_located((By.XPATH, "//section[@class='note-item']")))首先通过xpath表达式,获取网页上的搜索框,通过send_keys()方法写入我们想要搜索的关键字,再获取到搜索按钮,通过click()方法点击按钮,实现搜索,然后通过xpath表达式,获取页面上表示内容的note-item元素,我们先来分析一下小红书搜索页面的内容元素。如图所示:
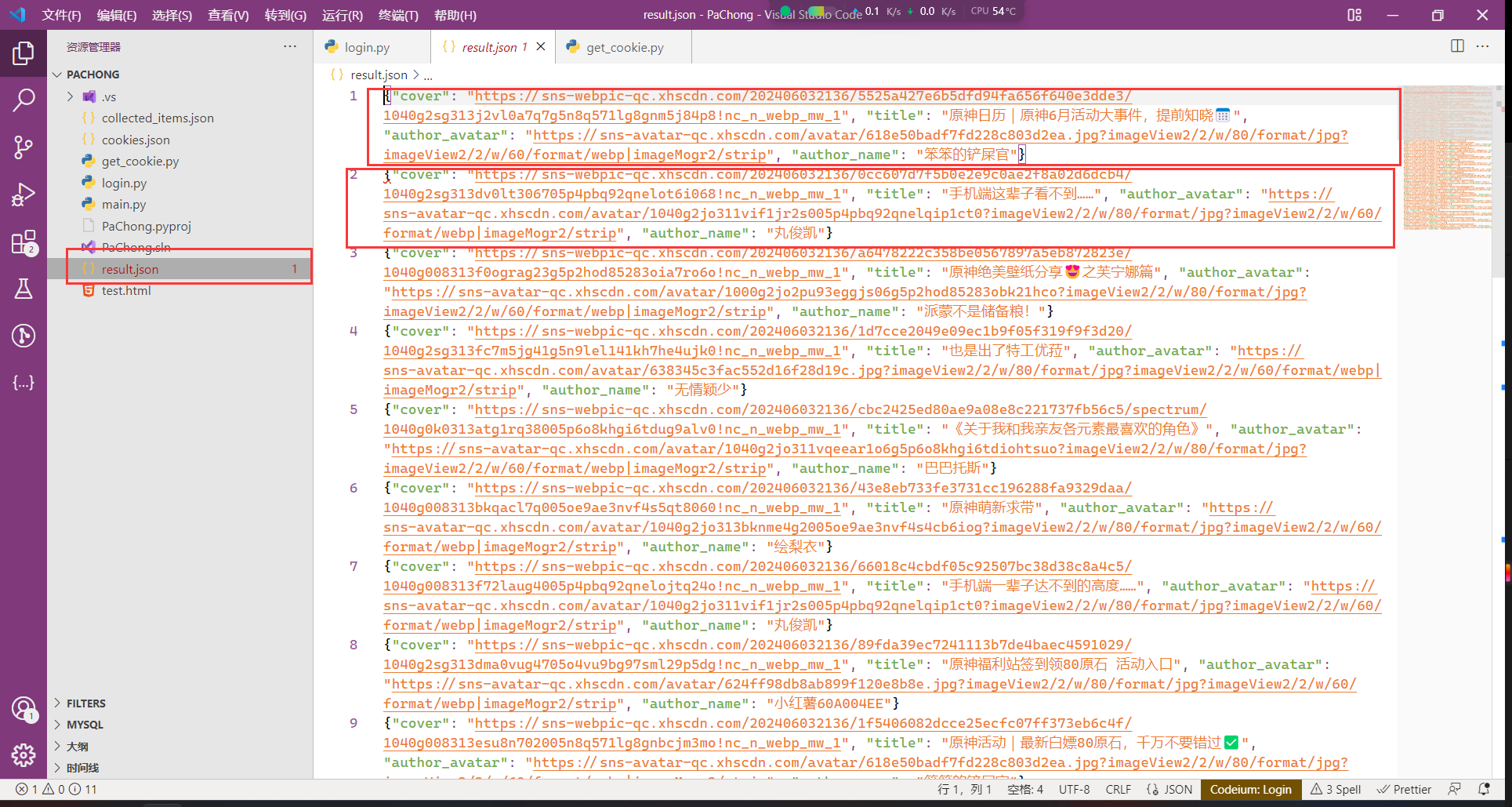
通过分析页面元素我们可以看到,每一个内容卡都对应着一个class="note-item"的section选项卡,点开section选项卡我们看到包含内容封面、标题、作者头像和作者昵称等信息,也就是说,我们可以通过代码,获取主页上显示内容的所有封面、作者等信息,并保存到本地。下面来看具体实现,给出完整代码: import json from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import NoSuchElementException import random import time # 设置 ChromeDriver 路径 chrome_driver_path = "D:/JIAL/JIALConfig/chromedriver/chromedriver.exe" MAX_ITEMS_BEFORE_WRITING = 20 # 每收集 20 条数据就写入一次文件 def write_to_file(collected_items): # 追加写入文件的逻辑 with open('result.json', 'a', encoding='utf-8') as file: json_data = [json.dumps(item, ensure_ascii=False) for item in collected_items] file.write('\n'.join(json_data) + '\n') print("Results saved successfully.") #随机延时函数,用来模拟动作比较快的点击操作 def random_delay(time_start, time_end): delay = random.uniform(time_start, time_end) time.sleep(delay) # 配置 Chrome 选项 options = Options() options.add_argument("--disable-blink-features=AutomationControlled") driver = webdriver.Chrome(service=Service(executable_path=chrome_driver_path), options=options) driver.maximize_window() def scroll_and_collect(driver, num_items): collected_items = [] collected_count = 0 result_count = 0 while result_count < num_items: # 获取了页面上的所有选项卡 items = driver.find_elements(By.XPATH, "//section[@class='note-item']") # 遍历获取的列表,分析里面的元素 for item in items: try: # 找到元素里封面、标题、作者昵称、作者头像等元素 cover = item.find_element(By.XPATH, ".//div/a[@class='cover ld mask']/img").get_attribute("src") title = item.find_element(By.XPATH, ".//div[@class='footer']/a[@class='title']/span").text author_avatar = item.find_element(By.XPATH, ".//div[@class='author-wrapper']/a[@class='author']/img").get_attribute("src") author_name = item.find_element(By.XPATH, ".//div[@class='author-wrapper']/a[@class='author']/span[@class='name']").text # 存储获取的结果 collected_items.append({ "cover": cover, "title": title, "author_avatar": author_avatar, "author_name": author_name }) result_count += 1 collected_count += 1 # 写入文件 if collected_count >= MAX_ITEMS_BEFORE_WRITING: write_to_file(collected_items) collected_items = [] # 清空已收集的项 collected_count = 0 # 重置计数器 except NoSuchElementException: continue # 翻页 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") random_delay(4, 8) # 等待页面加载新的内容 # 等待新内容加载的逻辑 try: WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.XPATH, "//section[@class='note-item']")) ) except NoSuchElementException: break # 最后一次写入剩余的项 if collected_count > 0: write_to_file(collected_items) return collected_items try: # 打开小红书主页 driver.get("https://www.xiaohongshu.com") random_delay(5, 10) # 等待页面加载 # 从文件加载 cookie with open("cookies.json", "r") as file: cookies = json.load(file) # 注入 cookie for cookie in cookies: driver.add_cookie(cookie) random_delay(2, 6) driver.refresh() # 刷新页面以加载注入的 cookie random_delay(5, 10) # 显式等待,直到搜索框出现 wait = WebDriverWait(driver, 10) search_box = wait.until(EC.presence_of_element_located((By.XPATH, "//input[@placeholder='搜索小红书']"))) search_box.send_keys("原神") random_delay(2, 5) search_button = wait.until(EC.element_to_be_clickable((By.XPATH, "//div[@class='input-button']"))) search_button.click() random_delay(2, 5) wait.until(EC.presence_of_element_located((By.XPATH, "//section[@class='note-item']"))) # 获取前100个内容的封面、标题、作者头像和昵称 num_items = 100 scroll_and_collect(driver, num_items) # 延时几秒以便查看搜索结果 time.sleep(60) finally: driver.quit()首先我们获取页面中所有的内容选项卡,再遍历获取的内容,对每一个选项卡都进行内容分析,获取里面包含的封面、标题、作者头像、作者昵称等我们需要的数据,储存起来,然后进行写入文件操作,具体的实现注释都显示在代码里,这里不做过多赘述。等待代码运行结束,你的根目录会出现result.json文件,这就是我们自动获取的数据信息了,如图所示:
这就是我们的最终结果,自动化批量获取到了网页上我们需要的数据。 五、注意事项 大家应该注意到了,代码中在每一个重要操作之后都加入了延时函数:random_delay(time_start, time_end),这是一个简单的随机延时函数,目的是模仿人的操作。因为大家手动操作,加上网络延时加载信息,不可能像代码一样,无间断操作,所以加入延时函数,一是为了防止网络延时元素未加载的问题,二是模仿人为操作,减少被反爬虫屏蔽的风险。 最最重要的一点,这样做也可以减少服务器负担,我们所做的获取数据操作,不应该以损坏服务器为代价,我们要在合理的、合法的区间对代码加以运用以完成数据获取,如果不加入相应的延时处理,可能会导致短时间内服务器负载过高,对于目标网站可能会造成损害。
|
【本文地址】